MA (say "I'm wrong") vs ER (actually fix it) — All 9 models at Baseline
Methodology
Evaluation Design
100 expert-level tasks with hidden cognitive traps across 15 domains and 8 TICOS types. Baseline vs MetaCog conditions isolate causal effects.
5-Axis Rubric
PQ (15%) + MA (20%) + ER (25%) + ID (20%) + FC (20%). MA = declarative. ER = procedural metacognition.
Tri-Model Judge
GPT-5.2, Claude Opus 4.6, Gemini 3 Pro ensemble. Human validation: Cohen's kappa = 0.87.
Theoretical Basis
Nelson & Narens (1990) monitoring-control model. Dennett (1987) functional stance.
Why FINAL Bench Exists
Every existing AI benchmark measures what models know. None measures whether they know what they don't know. This is the most dangerous blind spot in AI evaluation.
The Blind Spot in AI Evaluation
What existing benchmarks miss — and what FINAL Bench measures.
Existing Benchmarks
Measure final-answer accuracy only
Single correct answer (A/B/C/D or pass/fail)
No visibility into reasoning process
Cannot detect confident wrong answers
No measurement of self-awareness
No error detection or correction signal
Saturating rapidly (MMLU > 90%)
FINAL Bench
Measures functional metacognition
5 independent axes per response
Full reasoning process evaluated
Separates "saying" from "fixing"
Quantifies self-awareness (MA axis)
Quantifies self-correction (ER axis)
Unsaturated — top model scores 68.71
Five Generations of AI Benchmarks
Where FINAL Bench sits in the evolution of AI evaluation.
Generation 1 — Knowledge
MMLU, ARC, HellaSwag
Static multiple-choice. Tests what the model memorized.
Generation 2 — Execution
HumanEval, MBPP, SWE-bench
Code generation. Tests what the model can do.
Generation 3 — Expert Reasoning
GPQA, MATH-500, MedQA
PhD-level expertise. Tests how deeply the model reasons.
Generation 4 — Open-Ended Judgment
Arena, MT-Bench, AlpacaEval
Human preference. Tests how well the model communicates.
Generation 5 — Metacognition
FINAL Bench
Tests whether the model knows when it's wrong and can fix itself. The prerequisite for AGI.
How We Measure: Baseline vs MetaCog
Two conditions isolate the causal effect of structured self-correction.
Condition A
1
Baseline
Single API call. No self-correction. The model's raw response.
vs
Phase 1
2
Initial Reasoning
First response generated. Same prompt as Baseline.
Phase 2
3
Critical Self-Review
Structured prompt to identify errors, biases, and assumptions.
Phase 3
4
Corrective Revision
Revised answer integrating self-identified corrections. No external feedback.
Five-Axis Evaluation Rubric
Each response scored on 5 independent dimensions.
PQ
Process Quality
15%
15%
Structured reasoning chain
MA
Metacognitive Accuracy
20%
20%
Declarative — "I might be wrong"
ER
Error Recovery
25%
25%
Procedural — detect & fix errors
ID
Integration Depth
20%
20%
Multi-perspective synthesis
FC
Final Correctness
20%
20%
Factual accuracy
8 TICOS Metacognitive Types
Every task classified by its primary cognitive challenge.
A
Trap Escape
Recognize and escape a planted cognitive trap
13
B
Contradiction Resolution
Detect and resolve contradictions within premises
7
C
Progressive Discovery
Revise understanding as new evidence accumulates
11
D
Multi-Constraint
Balance multiple competing constraints
10
E
Self-Correcting
Identify and correct errors in own reasoning
14
F
Expert Panel
Adjudicate between conflicting expert views
16
G
Pivot Detection
Recognize when a fundamental assumption must change
14
H
Decision Under Uncertainty
Decide and justify with incomplete information
15
Task Distribution
100 tasks across 15 domains and 3 difficulty grades.
Tasks per Domain
Grade Distribution
Deep Analysis
Visual breakdown of three principal findings from 1,800 evaluations across 9 SOTA models.
Finding 1: ER Dominance
94.8% of improvement from Error Recovery alone.
Five-Axis Contribution to MetaCog Gain
What This Means
94.8%
Error Recovery is virtually the only axis that changes when self-correction is applied.
IMPLICATION
The bottleneck to AGI is not knowledge or reasoning. It's about teaching models to detect and correct their own mistakes.
Finding 2: Declarative-Procedural Gap
All 9 models can say "I might be wrong" — none can reliably fix it.
MA vs ER — Baseline (All 9 Models)
MA (Declarative)
0.694
Models are good at verbalizing doubt.
ER (Procedural)
0.302
Models critically fail at actual correction.
Gap
0.392
The chasm between saying and doing. A 15x differential.
Finding 3: Difficulty Effect
Harder problems benefit dramatically more from metacognition.
Baseline Score vs MetaCog Gain (r = -0.777)
Lowest Baseline
Claude Opus 4.6 — 56.04
+20.13 gain
Highest scaffold receptivity. Rank 9 to 5.
Highest Baseline
Kimi K2.5 — 68.71
+9.83 gain
Already-high intrinsic ER (0.450). Less room.
MetaCog Gain by TICOS Type
100% win rate across all 8 metacognitive task types.
Mean Delta by TICOS Type
AI Safety Implications
The MA-ER Gap reveals a previously invisible risk: models that sound careful but fail to self-correct.
Two Safety Profiles
The MA-ER Gap is the first metric to distinguish these.
!
High MA, Low ER — "Humble Deceiver"
MA = 0.75 ER = 0.30 Gap = 0.45
Says "I'm not confident" — giving false reliability. Fails to correct. Users trust the humility. Errors propagate silently. All 9 SOTA models match this profile.
O
High MA, High ER — "Reliable Self-Corrector"
MA = 0.75 ER = 0.75 Gap = 0.00
Says "I'm not confident" — and actually fixes the error. Self-correction aligns with self-awareness. Target for safe AGI. No model achieves this at Baseline.
Real-World Risk Scenarios
The MA-ER Gap has direct consequences in high-stakes domains.
Medical Diagnosis
AI says "this diagnosis has uncertainty" but presents the same incorrect recommendation. Patient receives wrong treatment.
Legal Analysis
AI hedges with "interpretation may vary" but doesn't correct the flawed precedent. Brief contains incorrect case law.
Financial Modeling
AI notes "projections carry uncertainty" but doesn't fix the unit error. Investment decision based on wrong data.
Autonomous Systems
AI logs "sensor confidence: 72%" but doesn't adjust its plan. Wrong action executed in physical world.
MA-ER Gap by Model — Risk Ranking
Higher gap = higher risk.
MA-ER Gap at Baseline — Sorted by Risk
Research Paper & Key Figures
Visual evidence from 1,800 evaluations across 9 state-of-the-art models. Each figure illustrates a core finding of the FINAL Bench framework.
📄 Official Paper
FINAL Bench: Measuring Functional Metacognitive Reasoning in Large Language Models
Taebong Kim, Minsik Kim, Sunyoung Choi, Jaewon Jang
9 Models × 30 Tasks — The complete performance landscape
Key Insight
Left panel: Kimi K2.5 leads with 78.5 FINAL Score, but the ranking shifts dramatically between Baseline and MetaCog conditions. Claude Opus 4.6, ranked last in Baseline (56.04), leaps to 5th place (76.17) under MetaCog — demonstrating the highest scaffold receptivity of any model.
Right panel: MetaCog gain (Δ_MC) is inversely correlated with Baseline performance. Claude Opus 4.6 gains +20.1 points while Kimi K2.5 gains only +9.8. This establishes that models with the most room for improvement benefit most from structured self-correction.
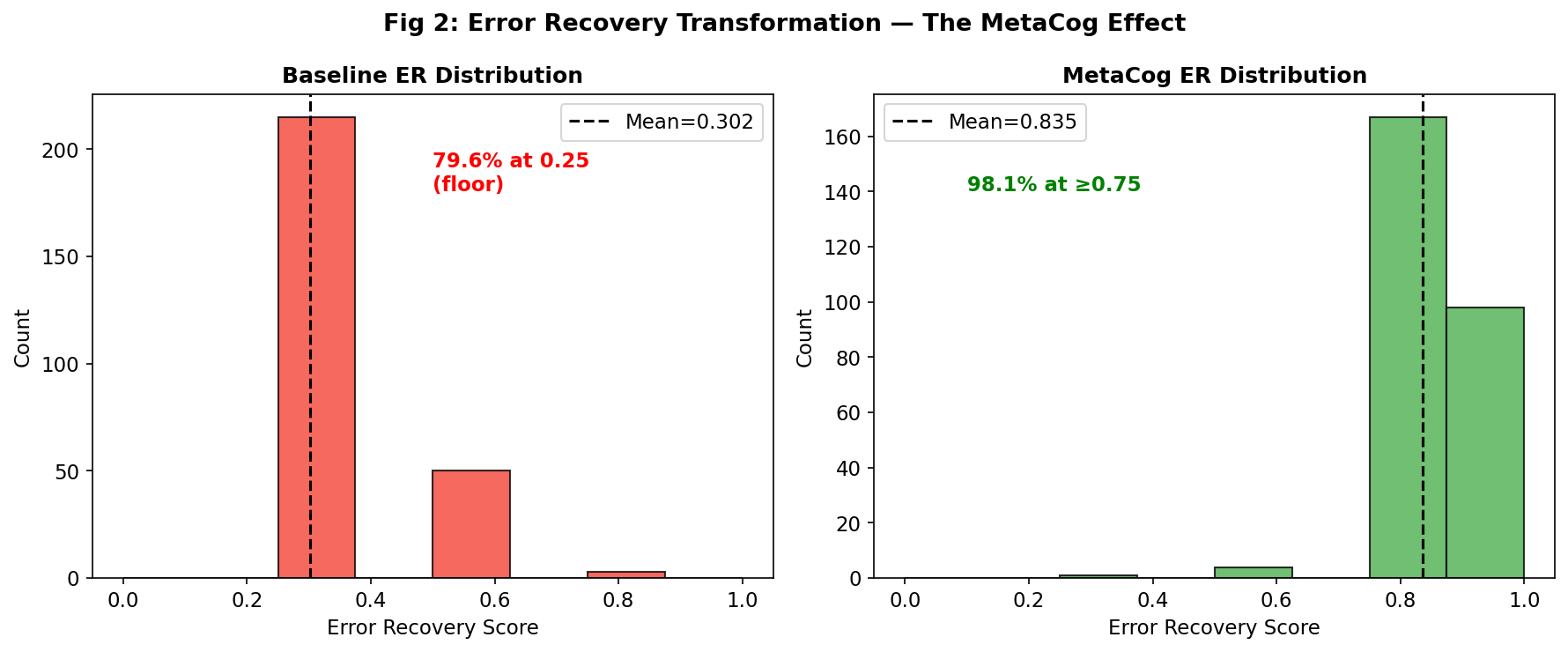
FIG 2
Error Recovery Transformation — The MetaCog Effect
How self-correction scaffolding transforms the ER distribution
The ER Floor Effect
Baseline (left, red): A catastrophic floor effect — 79.6% of all evaluations score at the minimum (ER = 0.25). Mean = 0.302. Without self-correction scaffolding, models almost never detect and fix their own errors.
MetaCog (right, green): A dramatic shift — 98.1% of evaluations now score ≥ 0.75. Mean jumps to 0.835. This is the single most striking visualization in the paper: the entire distribution migrates from floor to ceiling. Error Recovery is a latent capability that models possess but cannot activate without structured prompting.
FIG 3
Declarative-Procedural Gap
Baseline (○) → MetaCog (□) transition for all 9 models
The "Can Describe, But Cannot Fix" Phenomenon
This scatter plot maps Metacognitive Accuracy (MA, x-axis) against Error Recovery (ER, y-axis). The dashed diagonal represents MA = ER (no gap).
Baseline circles (○): All 9 models cluster in the pink "GAP ZONE" — high MA but low ER. They can verbalize uncertainty ("I might be wrong") but fail to act on it. This is the Declarative-Procedural Dissociation, analogous to the monitoring-control gap documented in human cognitive psychology (Nelson & Narens, 1990).
MetaCog squares (□): After scaffolding, all 9 models migrate upward into the green "ALIGNED ZONE" where ER ≥ MA. The arrows show the transition — movement is almost entirely vertical (ER increases while MA barely changes), confirming the ER Dominance finding.
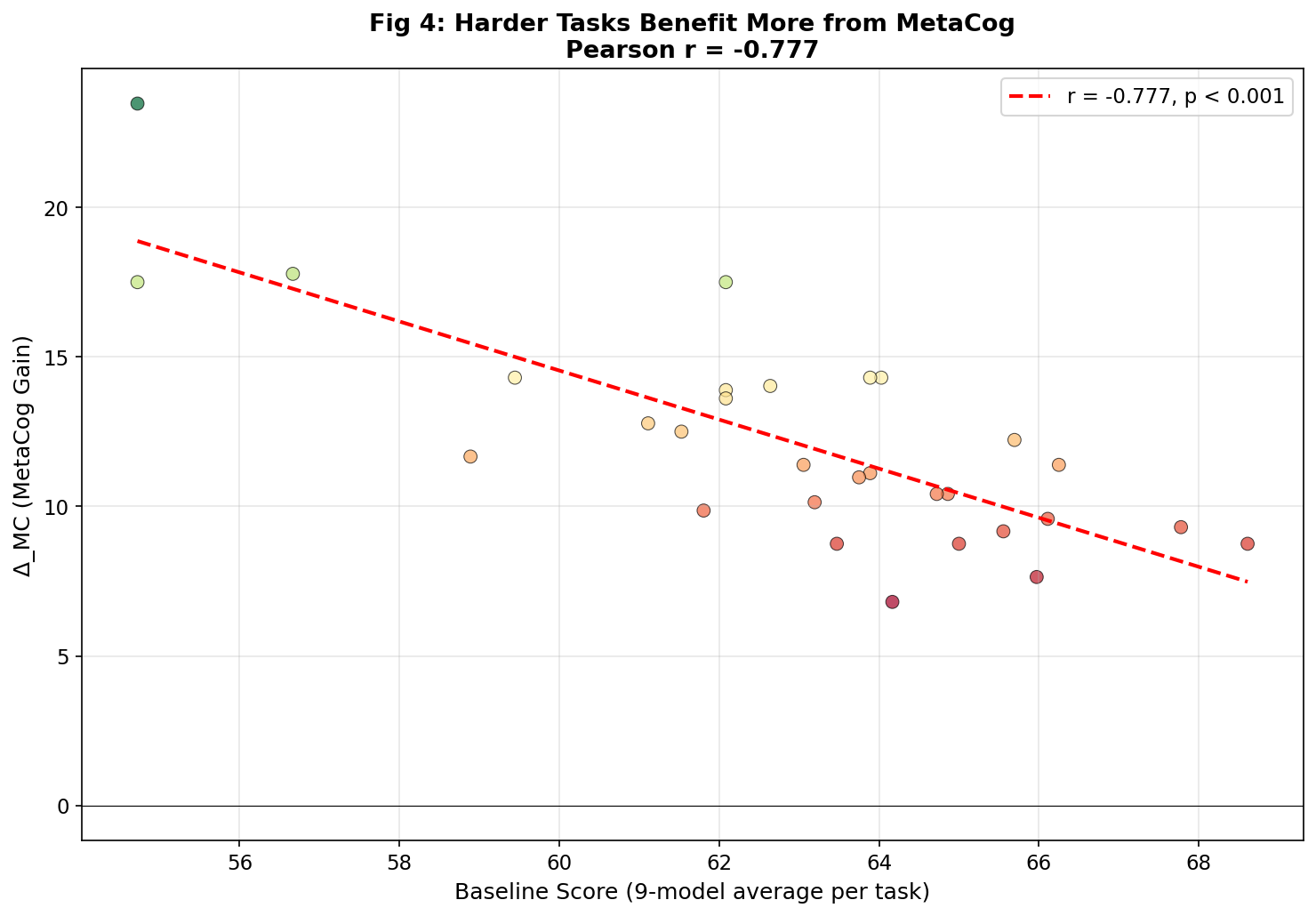
FIG 4
Difficulty Effect — Harder Tasks Benefit More
Pearson r = −0.777, p < 0.001 across 30 tasks
Finding 3 — The Difficulty Effect
Each dot represents one of the 30 evaluated tasks. The x-axis shows the 9-model average Baseline score (lower = harder task), while the y-axis shows MetaCog gain (Δ_MC).
The strong negative correlation (r = −0.777, p < 0.001) reveals a critical insight: the harder the task, the more metacognition helps. Tasks where models score ~54 at Baseline gain up to +23 points with self-correction, while tasks scoring ~68 gain only ~9 points. This implies that metacognitive scaffolding has the greatest impact precisely where it matters most — on frontier-difficulty problems where models are most likely to fail silently.
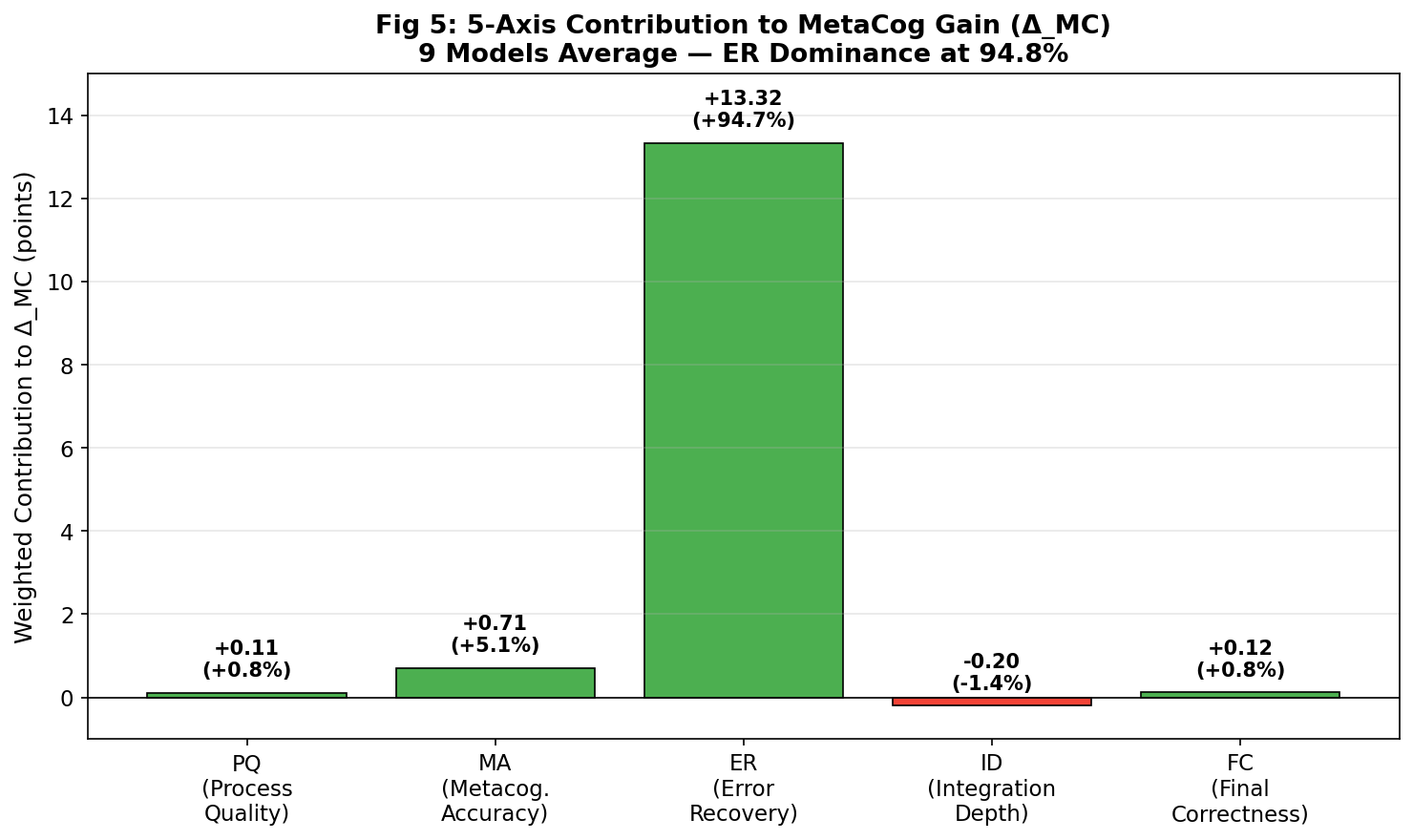
FIG 5
5-Axis Contribution to MetaCog Gain
ER Dominance at 94.8% — The single bottleneck to AGI-level reasoning
Finding 1 — ER Dominance
This bar chart decomposes the total MetaCog gain (+14.05 points) into weighted contributions from each of the 5 rubric axes, averaged across all 9 models.
The result is unambiguous: Error Recovery (ER) contributes +13.32 points (94.8%) of the total improvement. Metacognitive Accuracy adds a modest +0.71 (5.1%), while Process Quality and Final Correctness contribute less than 1% each. Integration Depth actually decreases slightly (−0.20), consistent with the token competition hypothesis — self-correction tokens consume budget that would otherwise go to synthesis.
Bottom line: The path to AGI-level reasoning is not broader knowledge, deeper reasoning, or better expertise. It is teaching models to detect and correct their own errors. Everything else is already there.